2023年雑振り返り
何も書かないよりはいいかなと思い、雑に振り返る。
バスケ
3年前に膝を手術して以降、めっきりやっていなかったバスケを再開した。 というのも引っ越し先のスポーツジムでバスケができることを発見し、ガチすぎず体育の授業のような雰囲気でリハビリにはちょうど良かったためである。
リハビリのつもりであったがバスケが楽しくなってしまい、結局週2, 3ペースで1年間通い続けている。 そのためかデスクワークで癖になっていた肩こりや腰痛が本当に激減した。
また、ジムにはしっかりめのサウナと水風呂も設置されていて、バスケからのサウナが最高すぎる。 これのおかげで一年間元気にやってこれたと言っても過言ではない。
バスケ熱が高まっているので近所でクラブチームを探し中。
お仕事
2022年11月に転職し新天地で働き始めて1年が経った。 10年近くプロダクト開発1本でやってきたが、新天地では組織横断系の開発部署にTPM(テクニカルプログラムマネージャー)として参画し今に至る。 これまでいた環境とは違う力学だったり、課題だったり、日々新しい発見と向き合いながらお仕事している。
しかし、今年1年を振り返ると、仕事の内容というよりは自分自身のコンディショニングに悩まされた1年であった。 転職前のある時期にメンタル起因で体調を崩し、それ以降調子があまり戻っておらずパフォーマンスが不安定な状態が続いていた。 1年間試行錯誤で働き方・作業環境 etc... を試した結果、やっと11月頃にパフォーマンスが安定してきた感覚がある。
正直自分がこんな状態になるなんて思ってもみなかったが、こればっかりは論理だけで解決できる問題ではないので、うまく付き合って楽しくお仕事していきたい。
お仕事自体は、どのような環境でも自分のケーパビリティを100%出せるように再現性を上げることが自分の中でのテーマである。(今年というかここ数年でのテーマである) 会社の状況的にも変化が大きいタイミングで、「やれることをやる」というのが比較的難しい状況ではあるが、自分が得意とすることの再現性を高めて自分の中での確かなケーパビリティに昇華させて、それを足掛かりに成長していきたい。
子
2歳後半に差し掛かり、最近はおしゃべりも上手になってきた。 複数の事柄を時系列順で体系立てて喋ったり、数字やアルファベットが長く言えるようになったり、進化のスピードが著しい。 自分がフルリモートで家に籠りっきりなので、保育園から帰ってきたらお喋り相手になっていただいている。
また、自分に似てしまったのか周りの子と比べても圧倒的に人見知りだったのに、最近は初対面の人に会ってもすぐに慣れて話しかけ始めるのでその点は良かった。多くの面で性格や志向性が自分に似すぎているのだが、そこは妻に似てください。
家事育児の負担割合は少なめに見積もっても妻と自分でイーブンなのに、ママっ子が発動する率が高いのは寂しさを感じていた。やはり母というのは偉大であると痛感せざるを得ない。 でも最近はパパっ子の時間帯の方が長くなってきたため報われた気に勝手になっている。
この1年間は子を連れてお出かけする行動範囲が広がったものの、行く場所はマンネリ化しているので、来年はあまり開拓できていない博物館や美術館にも行ってみたい。
車
去年ソリオを買ったばかりなのに、1年でオーラに乗り換えた。
自分が言うのもあれだが、ソリオはマジで良い車である。広い、運転しやすい、スライドドア、コンパクトなど3人家族にとっては最適解ではないかと思う。
では何故乗り換えたかと言うと、なんとなしに試乗でオーラに乗り、その体験の良さに衝撃を受けたからだ。 自分は車に詳しい方ではないので細かい話はできないが、最初にアクセルを踏み込んだ瞬間のフィーリングが良すぎて一瞬で惚れ込んでしまった。 ソリオもよい車であるものの、広すぎて空調が聞きづらい(3人家族なのでそこまで広さはいらなかった)、構造上高速で風に煽られやすいなどの不満ポイントがあったのも乗り換えを後押しした。
オーラに乗り始めて数か月が経過したが、まじで買ってよかったと思っている。
移住
ちゃんと検討しているわけではないが、移住が気になっている。 生活費の多くを占めるのは居住費でありそれを削減したいというのが主な理由である。
また、仕事において比較的土地の縛りが緩くなった昨今の状況を考えると、 自分たちの生活スタイルにおいては移住しても楽しく過ごせると思っている。
ただ、いかんせん膨大な候補がある中で、インターネットで調査をし、 複数の判断軸から一つに決め切って、そこに引っ越すという決断をするハードルはとても高い。 実際に訪れてそこに惚れ込むなど、もっとエモーショナルな出来事がないと移住には踏み切れない。
子が小学生になるまでに結論を出したいので、毎年2か所くらいは実際に訪れてみようかなとは思う。 ちなみに今は沼津が気になっている。
今年1年お疲れさまでした、来年も頑張ろうな。
意思決定に関するメモ
自分はなんちゃらリーダーだったりなんちゃらマネージャーという肩書のもとお仕事をすることが多く、日々いろんな意思決定を行ってきた。 そんな中で「意思決定って難しいよね」なトークを社の人としていて、気付きがあったのでメモ
正解は無い
意思決定というのは、大前提何が正しいものか分からない中で行うことが大半である。 極端な話、正しいものが何かが明確な状態でそれを選択することは意思決定とは言わない。
人間生きているからには正しいことをやりたい人が多いと思うので、なるべくその確度を上げるために議論を重ねたり、情報収集をしたりなど努力を重ねる。しかし、最終的には正解には辿り付かない状態でAかBかを決める必要があるということを踏まえておかねばならない。 そういうこともあって、何が正しいのか?の見極めに時間を使いすぎることは決して良い選択とは言えない。
また、正解に辿りつくことは無いとしたときに、選択を誤る可能性はもちろんゼロではない。 何かを選択するということは、選択しなかったことのリスクを一定許容するものである。 これはリスクコントロールしましょうという話ではなく、勇気を持ってリスクテイクしような、という考え方がよいのかなと思っている。
満場一致を望まない
何かを意思決定する際に、ステークホルダー全員が心から賛同している状態が望ましいのは言うまでもない。 しかし、現実はそうもいかない。 前述の通り正解は無いという状態のもと、人間それぞれの価値観・環境・立場・その他様々の違いがある中で、満場一致で意見が揃うということはそうそう無いからだ。
したがって、何かの意思決定を推進する立場にいるのであれば、全員の賛同が得られない中、AかBかを決定し進めていく必要がある、ということは踏まえておきたい(自分と一緒に仕事したことある人は分かると思うが自分は皆の納得・賛同を欲しがりがち) それは反対意見は気にしてもしゃーないから無視して進めようということではなく、AかBか意見が割れていても、1段抽象度を上げたαに関しては意見が揃っている、という状態は必要かなと思う。
意思決定の舵を持たないという選択
意思決定を行うには、多くの情報が必要不可欠だ。 一方で新しい環境に入ったばかりの頃は、その領域におけるドメイン知識が大きく不足している。 そこでドメイン知識をキャッチアップし、”自分が” 意思決定を主体的にできるように努力することはもちろん大切である。
一方で何故意思決定をするのかを考えてみると、何らかの事柄を前に進めたいからであって、そこに "自分が" 意思決定できるようになることは必須条件ではない。 従ってドメイン知識のキャッチアップはもちろん重要ではある一方で、意思決定の舵を持たない(=代わりに意思決定してくれる人を探す)ということは同じくらい重要である。
意思決定に関して深堀りしていくと結局のところ要はバランスおじさんみたいな話にはなってしまうのだが、自分の行動・思考パターン的にここはポイントだなと思うことの雑メモであった。
ぼくが考えた最強のリモートワーク環境 〜2022春〜
リモートワークで何使ってるかという話が直近N回出たので書いておく
結論

以前はもっと色々デスク上に置いていたり、ディスプレイの枚数も多かったのだが、 そんなにいらねぇだろ!!と自分の中でなり、昨今はシンプル is ベストに回帰している。
デスク
FlexiSpot | EJ2 に TABLE TOP BOARD – KANADEMONO の天板を利用している
会議が多い日や気分転換したいときはスタンディングで作業しているが、ぶっちゃけ使用頻度はそこまで高くない。 (健康のためにもっと活用したほうが良い気はしている)
椅子
長らくニトリのワークチェアを利用していて特に不満はなかったのだが、妻に椅子を譲ることになりこのタイミングで高級なワークチェアに変えた。 WORKAHOLIC I ワーカホリック に行って色んな椅子を試しに座ったのに、デザインと機能面で座ってないリープチェアを気に入ってしまい勢いで購入。結果オーライだが身体にも合っていて、腰痛が明らかに軽減された。
(ちなみにワーカーホリックは椅子に座れるだけでなく、椅子の座り方・高さの考え方などなどをゼロから教えてくれるのでめちゃくちゃ良かったです)
ディスプレイ
かつては32インチの4Kモニターに、左に24インチを縦置き、右にMacを開いて3枚構成で運用していたが、首を左右に振る頻度が増えるからなのか、いつからか首が痛くなるようになってきた。
ということもあって1枚で表示領域が広いウルトラワイドディスプレイに。 Macはクラムシェルにしている。
本当はディスプレイ1枚で片付けたいのだが、たまにTeamsで会議しているとMacが超絶重くなるので予備としてiPadを設置。
ディスプレイ周りの配線
ポリシーとしてはディスプレイに配線を集めてMacにはUSB-C1本刺すだけにする&他はbluetoothで接続
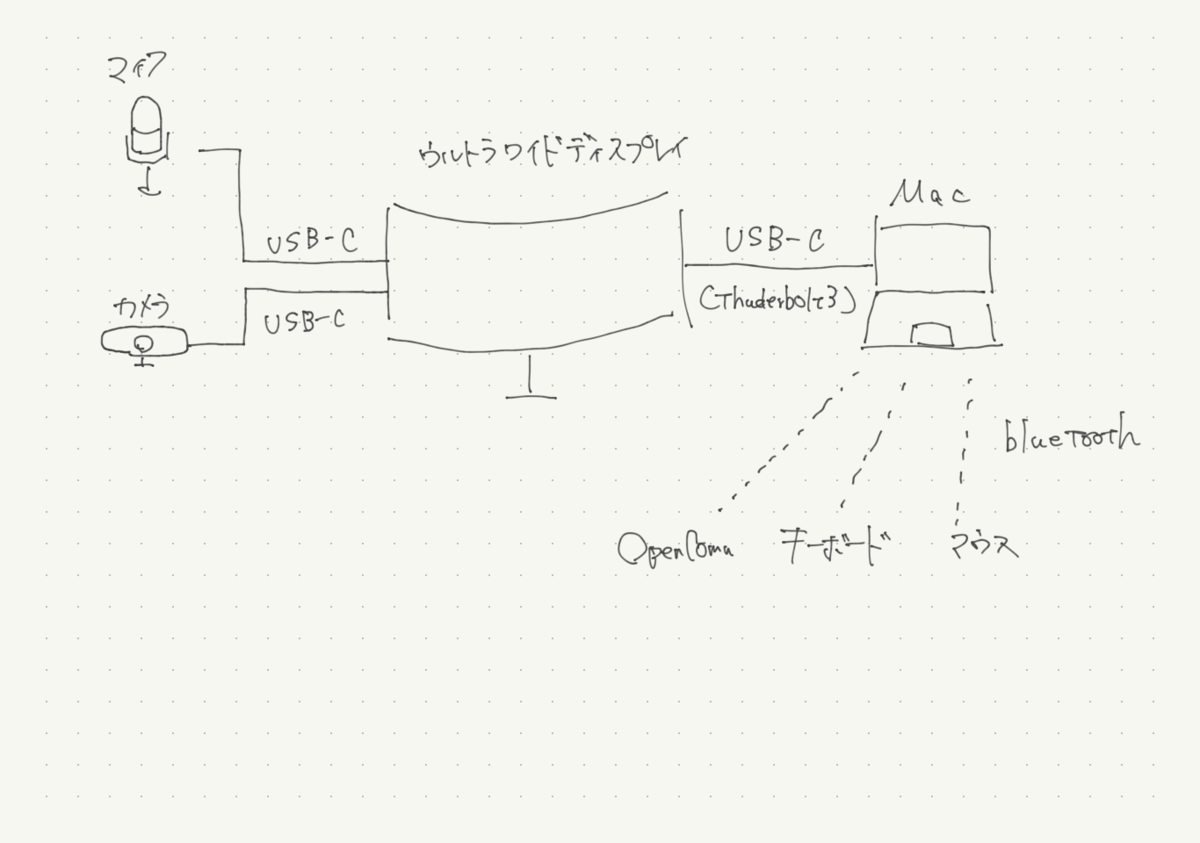
オーディオインターフェースが鎮座すると場所をとるため、使わない前提で各種デバイスを選んでいるが、正直あのメカメカしい感じに惹かれる。
キーボード
趣味で大量のキーボードを保持しているので、気分でローテしている。 メインはchoco60(自作キーボード)、左右分離キーボードを使うと肩こりなど皆無で最高です。
他には以下をよく使っている
Happy Hacking Keyboard Professional HYBRID Type-S 日本語配列/墨|PFUダイレクト Mistel BAROCCO MD770 左右分離型キーボード - 株式会社アーキサイト Air75 Wireless Mechanical Keyboard Keychron K6 Wireless Mechanical Keyboard
マウス
もうかれこれ5年以上はトラックボールがメインな気がする。 Magic Trackpadも3点のジェスチャーが大変便利なのだが、手首の負担という点で自分の中ではトラックボールのメリットが優っている。
マイク
最近使い始めたばかりなのでなんとも言えんが、ダイナミックマイクでそこそこ音質が良い、USB接続が可能で取り回ししやすいという点で採用
WebCam
Anker PowerConf C300www.ankerjapan.com
ここはこだわりがあるわけではなく、同僚が使っていて良さそうだったので購入
リモート会議時のイヤホン
イヤホン装着時の自分の声が脳内に跳ね返ってくる感じが嫌いで、骨伝導イヤホンを利用。 骨伝導は本当にストレスフリーでもう手放せない。 骨伝導といえばAfterShokzかと思うが、その中でも連続通話時間が長いOpenCommを採用。
音楽聴くときのイヤホン / ヘッドホン
Nothing ear (1)jp.nothing.tech
何より見た目が超クール。かつ値段の割に音質が良い。
BOSEの中でも後継機が出てたり、他メーカーでも新しいものはあるのだが、これがめちゃくちゃ軽くて装着感が良いため、パッドを交換して長く使っている。(ガジェットはすぐ新しいものに買い替えてしまうのだが、これは自分が保有しているものの中でも最も長く利用している気がする)
スピーカー
元々はBOSEの有線スピーカーを設置していたが、ちゃんと音楽を聴きたいときはヘッドホンを利用していることに気づいて、コンパクトなものに。 主にPodcastや作業時のBGM再生に利用。 LIVEモードが優秀で、左右分離するタイプでない割にはサラウンド感が得られる。
二酸化炭素濃度計
間取り上空気がこもりやすく、あまりにも空気が悪いので妻が買ってくれた。 部屋を締め切っているとみるみる数値が上昇していくので、常時換気の大事さを思い知る。
コップ
🎊ヴィレヴァンオンライン新グッズ🎊
— もくもくちゃん (@mok2mok2) 2019年7月16日
なでなでしてほしいウサギとアザラシがシュガーになりました🥺💕
新しいマグカップも!!
セット販売のものもあります🌸
予約受付中です🐰❣️https://t.co/DYv10jsdlO pic.twitter.com/rR7Dq45w34
もくもくちゃん
カレンダー
宮古島が好きで毎年行っており、沖縄出身でもないのに結婚式も挙げたのだが、コロナになってから一回も行けていない。 今年こそ行けたらいいなぁ
モルカー
モルカーにハマり、羊毛フェルトで手作りした者たち。PUI PUI!!
その他気になっているもの
使いこなせるきはしないのだが、StreamDeckを使ってみたいなぁと思っている。
日進月歩で色々なリモートワークグッズが出てくるし、自分の嗜好性が変わってまたマルチーモニター構成に戻るかもしれないし、「最強リモートワーク環境の戦いはこれからだ!!」かもしれない
いろんなことに口を挟まなくなった話
susunshun.hatenablog.com これの続編
最近いろんなことに口を挟まなくなったので雑メモ
4月から担当するプロダクトが変わったことによる環境の変化がデカいと思っている。
どうせコントロールできんという話
これまでは割と若めのプロダクトを担当することが多く、携わるステークホルダー全員の顔と名前はわかる規模感であることが多かった。 なのである程度全体を把握し、各所に入り込んでいく動きが可能だったのかと思っている。
一方で、今回は歴史あるプロダクトということもありその運営に携わるステークホルダーは膨大で、エンジニアに絞っても自分が認識していない人がきっと多くいるのであろう。
そういう規模感のプロダクトなのでビジネス・システム・組織・プロセス etc.... 全体を解像度高く理解することはとてもじゃないができない。 もともと自分がマイクロマネジメント気味に動いてしまうことに課題感を持っていたと共に、どうせ全体をコントロールできないのであれば任せたほうが健全である、思えるようになったのである。裏を返せば、パワーを注ぐ領域を見定めてフォーカスしないと何も成せないということがわかった。 (ただし現実世界に目を向けて見ると、今はあまりにも任せすぎというか、情報を獲得してとりあえず知っておくということすら充分にできておらず、口を挟まないどころかほとんど喋らないおじさんになってしまっている気がするのでそれはそれで良くない。口を挟まないことと知ろうとしないということは別なので)
何かヤバかったらなんとかするという話
環境の変化がフックとなり、良い意味でマイクロマネジメントに対するあきらめが自然と出てきた。 それとは別に「何かヤバかったら最終的に自分が入って鎮火すればよい」という覚悟というべきか、根拠の無い自信というべきか、そのような感情も持つようになった。今の会社に入ってから時を経てそこそこ経験を詰んできたからなのか、いまのチームで自分の年次が上から数えたほうが早いからなのか、要因は正直分からん。そしてほんとにヤバかったら鎮火できるかも正直なところ分からん。
ともかくヤバそうになってから初めてヘルプに入ればよく、それまでは自由に立ち回ってもらったほうが、成功したらハッピー、失敗してもそれはそれでリアルな経験を詰むことができたのでハッピー、自分も相対的に可処分時間や脳内リソースも空くしハッピー、何も悪いことはないじゃんと。
ただし「ヤバそう」の線引きは重要で、例えばプロダクトに重大なインパクトを与えるようなトラブルが発生してから入るのではタイミングが遅い。しきい値までは完全に任せつつも、それを超えたら積極的に入り込んでいくことが大事だ。(会社でこの類の話をした際に「ガードレールを敷く」という表現が出てきて良さそうと感じた
皆が一段視座を上げるという話
だんだん冒頭と関係無い話になってくるが、組織ないしチームに携わる人間が全員一段視座を上げて生活している状態が理想なのではと思うようになった。メンバーならリーダーの視座を、リーダーならマネージャーの視座をというような状態だ。 それぞれが一段視座を上げることで相互理解が促進し、戦略の目線合わせが円滑に進むようになるのではと思ったりしている。また、リーダーやマネージャーのやる仕事について、彼らがやらねばならないという仕事はそこまで多くないでは?と仮説を置いており、権限委譲もしやすくなるのではと。 (メンバーがマネージャーの視座を、までいくとそれぞれの果たすべき責任・役割もある中で、ノイズが大きくなってしまうのではという心配はあるが、どうなんだろうな) 他にもキャリア・組織運営系の本や記事を漁れば「視座上げること」のメリットは無限に出てくるだろう。
いろんなことに口を挟まなくなったことで、リーダーっぽい仕事をしている自分は、マネージャーの視座を持とうという気持ちになり、彼らがどういう仕事にどういう脳みそを使い、どういうアウトプットを出すのかを主体的に考えるようになった。 これまでは、マネージャーの仕事はマネージャーのものなので任せるわ!!と思っていた節がある。
人に任せることが苦手だった自分が、なんだか最近任せられるようになってきたぞ!という話であった
余談
まだ任せる / 自分でやるの調整が下手で、「これは俺がやるやろ」と周りの皆が思ってそうなトピックに対して、これまでは「おっ、やっちゃうぞ!!!」と脳停止でなっていたとこをグッと堪えて「俺やらんからな!!」と明言したあとに、「やっぱり俺がやったほうがよいのではないか...むーん....」と悩んだりすることはあり、俺達の戦いはこれからだ!!!というお気持ちであります
ポジティブな意思決定をするという雑な話
お仕事をしていると何らかの意志決定を取るということは誰しもあると思います
そんな中で
「このシステムが負債がやばいので、こういう設計・実装を取るしかない」
みたいなマイナスなニュアンスの意思決定を取ったことはないでしょうか?自分はあります
ただこれはある種の脳停止だと考えており、いろんな可能性を潰している懸念があります。 結論は同じだとしても
「このシステムは負債がやばい。世で語られているベストプラクティスを適用するとリファクタの規模が大きくなるが、いまのプロダクト・チーム状況を踏まえると大規模のリファクタに投資するのは最適ではなく、こういう設計・実装をとるのがベストである」
といったように外部要因に意思決定を委ねるのではなく、 外部要因をインプットとして自分達が意思決定を取ってゆきたいと思っています。
ポジティブにやっていきたいという想いもありつつ、意思決定のオーナーを自分達に寄せることで振り返りやすくなるし、言語化していく仮定で課題に対する解像度も自ずと上がっていくのではないでしょうか
アーキテクチャの意思決定の履歴を残すプラクティスとしてADR(Architecture Decision Records)があったりしますが、こういったプロセスとしてではなく日常の振る舞いとして、油断すると「XXするしかない」という思考・発言をしがちなので意思決定のオーナーはワシらなんじゃ!という想いを大切にしたいよね(ポジティブな意思決定をするというよりかは意思決定のオーナーを持つという話だったかもしれない)
任せるということ
周りに言われて認識したのだが、自分は身の回りでメンバーが課題を抱えていたり、課題になりそうな煙が立つとかなり早い段階でサポート入って解決するようなムーブが多いらしい。意識したことはなかったがたしかにそうかもしれない
自分のタスクを権限移譲するという話ではなく、周りの成果を支援するという文脈
例えば調整ごとで難航していたら間に自分が入って整理したり、計画が弱くて実行がうまくいってなかったら一緒に計画したり、漏れているタスクがあったら拾ってシュッとやっちゃったり、様々である
ちなみにいままで「サポートに入らず完全に任せる」という行為は主に自分のキャパシティが限界だから負荷低減の主旨でやるのがメインだった
サポートに入るということは一見良さそうなムーブにも見えるが、過剰だと悪いこともたくさんあるので雑にメモしておく プラクティスが書いてある本は昨今たくさんあるが、あえて参照はせずにピュアに考えたことを書く
持続可能性の観点
課題がピュアに顕在化してこない、よくも悪くもなんとかしてしまう
自分が丸く収めることで物事が成立するので、組織・チームの成長のボトルネックになり得てしまい、スケールが難しくなってしまう 出るべき課題が出てこず、解消のタイミングが遅れてしまったりも考えられそう
個人的にはこのデメリットがデカイなぁと感じている
成長の観点
サポートに入ってしまうということは、試行錯誤の余地を削るということになりかねない、成長の機会を奪っているという解釈
それでも任せるのが難しいと思う所以
ほかにも色々デメリットがありそうだが、それを以ても主に心理的な面が足を引っ張り難しいなと感じることが多々ある
自分はチームの成果、プロダクトへの貢献を考えるとどうにも手を抜けない、万事を尽くしたいという想いでいつもやっている
それが早めにサポート入ってしまうというムーブにつながっている気がする。任せて失敗してもよいという発想ではなく、仮に失敗するとしても自分が入った上で失敗して自責にしたいのかもしれない
失敗してもよいじゃん、仮にヤバくなってから頑張ればいいじゃん、などなど寛容さが必要なのかなと思う
そして任せると言っても丸投げはよくない、皆が成果を最大化できるように必要なサポートはしていかなければならない
人によって持ってるスキルも、指向性も、性格も異なっているので、必要なサポートももちろん異なる
日々過剰な介入にならないための塩梅を探っている感覚があり、これが一番むずかしいと思う
つまり
いままで「もうタスク持てないから任せたわ!」というムーブが主だったけど、他にも任せることで良いことはあるよというのを再認識したので今後の自分のアクションが変わるかもしれない、でも任せるって難しい行為だよねという話
チームの改善を支える振り返りのポイント #KPT #振り返り
目次
まえがき
ここで言う振り返りは「KPT」や「レトロスペクティブ」など、チームで起きたことを振り返り、改善につなげるためのセレモニーのことを指しま(施策の効果測定、KPIモニタリングを指す振り返りではない)
GW明けから自分がいるチームで振り返りをやろうと思うので振り返りのTipsをメモしておきます ここに書くことはプラクティスの一つではありますが、ベストプラクティスではないかもしれません というのも振り返り一つとってもチームの状態によって取るべき方法論が変わるからです
ここでは - 1週間、2週間程度の定間隔で行う - 対象はチームにまつわるトピック という前提のもとで、自分が普段気をつけているポイントを記載します
振り返りの目的
端的に言うとチームでお仕事する上での諸々(プロセス、ルール、環境 etc...)の振り返りを定間隔行うことで、継続的な改善の種とすることだと考えています したがって振り返りをすれば課題が解消されるもののではなく、課題を可視化するまでの役割が主と捉えています
一方でKPTのKeepにあるように課題だけではなく、良いことも洗い出します これは前述の改善の成果/成功体験を皆で認識して継続及び横展開していくほか、その取り組みに閉じない文化を可視化する側面もあると思っています
これまで6プロダクト(チーム)で振り返りの装着/運用を行って来ましたが、Keepに出てくる内容はチームの特色が出ることが多く興味深いです
振り返りの方法
このような形式で行うことが多いです 一般的なKPTと若干差分があったりしますが、そこは後述していきます


気をつけていること
気軽に挙げられるようにする
振り返りの場では課題を漏れなく洗い出すために、モヤったことは気軽に挙げてもらいたいと考えています 人は時間が経つとモヤったことを忘れていく生き物なので、思いたったときにProblemを起票をするのがベストだと思いますが、ちゃんと書こうとすると「面倒だなぁ...」とか「これはまだ騒ぐほどじゃないから言わなくていいや」等々、何らかの障壁で起票をせずに忘れ去ってゆき、機を逃してしまうことも考えられます
この障壁を取り払うために、Keep/Problemの前段に「思ったこと」を設けて気軽にバシバシ起票してもらうことで、課題の種を漏れなく洗い出し、「これは課題だろうか?」というところから議論をチームで行っています
また、各論にはなりますが、Slackでkpt用のチャンネルを設けてそこに書いてもらったり、TrelloとSlackを連携してSlackから起票できるようにしたり、いつでも起票できる環境が望ましいかなと思います
チームの状態に応じてテーマ策定する
チームが発足した当初は多くの課題が眠っていて、Problemも大量に出てくると思います。 しかし、しばらくすると誰もProblemを起票をしなくなり形骸化...なんてことはないでしょうか?(僕はありました) 課題が全く無い完璧なチームであれば当然Problemも出てこないわけですが、そんなチームは存在しないと思います。きっと見えていないとこに課題が眠っているはずです この見えていない課題を、「皆が認識していない」「皆が暗黙的に認識しているが振り返りの場で出てこない」の2つに分割したときに、後者へのアプローチとして、振り返りのテーマを策定することが有効と考えます テーマを絞って具体度を上げることで、「思ったこと」を挙げやすくするためです

Tryは軽くする
Tryを設定したまではいいけどなかなか着手できず、どんどん溜まっていった結果全然捌かれない...といったことがかつてありました クリティカルな課題を解消したいときに、根本的な解消を望む場合にはどうしてもその動きは大きくなってしまうためです そんな大きい課題を取り扱う場合には、改善の一歩目を踏み出すためにTryを軽く設定しています
例えば... - 暫定対応と恒久対応に分け、前者はTryで実施、後者はチームのしかるべきタスクキューに詰む(ex. バックログ - 「【暫定対応】を実施」 - 「【恒久対応】をバックログに起票」 - ディスカッションが必要なTryであれば会議設定まで - 「〇〇の会議を設定し、それを受けてアクションリストが明確になっていること」と設定する - そのあとアクションをどう捌くかは次回の振り返りで議論
一方でTryを軽くするあまり、あまり効果のない対応を敷いてしまわないように注意は必要です その課題のissueを見極めて、段階的に解消を行うSTEPを意識することが大事だと考えています
やらないやつはやらない
KPTのフレームで振り返りをやっていると、Problemに対してなにかしらのTryを設定しなければならない力学が働きがちです しかし、タイミングによっては今はアプローチできないものであったり、構造上解消ができなかったり(しづらい)、そもそもこれは課題なんだっけ?というものもあります
主目的は課題を可視化すること、次に改善の一歩目を踏み出すことと捉えており、Tryを機械的に設定して捌くことではありません。やるべきことと、やらないことを分けて考える必要があります
このようなProblemに対しては「また困るならば再度Problemに上がってくる」と割り切って、「今はやらない(今じゃない)」「これはProblemではない」「課題認識までに留める」等々Tryを設定しません 後のために、起票されたProblemは「やらないこと」レーンに移動し、やらない理由と共に記録しておきます
あとがき
これまで振り返りを装着していく中で実践したTipsを記載しました 今後ももちろん継続して振り返りは実施していくので、今後新たに気づきがあればここに追記していこうかなと思います
また、今回記載したのはあくまでも振り返りという1セレモニーに閉じた内容ですが、このような改善の取り組みにはチームの文化形成やゆとりの創出、ステークホルダーとの信頼醸成も欠かせないと思っています。 継続的に改善ができるチームをこれから作っていきたいぞ!と思った際には是非そこらへんも意識しながらトライしてみると良いかと思います(偉そうに言っていますが、自分もまだまだ試行錯誤です)